网络空间安全学院任一支教授团队又一论文被国际顶级期刊IEEETIFS录用
来源:杭州电子科技大学 时间:2025-03-28 19:24
近日,网络空间安全学院任一支教授团队论文《Unstoppable Attack: Label-Only Model Inversion via Conditional Diffusion Model》被网络安全领域的国际顶级期刊《IEEE Transactions on Information Forensics and Security》录用。IEEE TIFS是国际网络安全领域的顶级期刊,中国计算机学会(CCF)推荐A类期刊,中国密码学会(CACR)推荐A类期刊,中国科学院SCI一区TOP期刊。
该项研究成果由杭州电子科技大学与中国工程物理研究院合作完成。论文第一作者是网络空间安全学院2021级研究生刘容轲,指导教师是任一支教授和王冬博士,刘容柯同学目前已经在IEEE TIFS、《电子与信息学报》《通信学报》等发表论文3篇,即将前往南京航空航天大学攻读博士学位。
目前人工智能中的隐私攻击可分为模型隐私攻击、数据隐私攻击两类,其中模型隐私攻击为模型萃取攻击,数据隐私攻击为推理攻击与重构攻击。团队重点关注重构攻击中的模型逆向攻击(Model Inversion Attack, MIA),即敌手通过访问目标模型,重构训练集数据、敏感属性或输入数据。相比于其他隐私攻击,该攻击揭示了训练集数据的“细粒度”信息,因此所造成的数据隐私威胁更大。此外,由于实际应用对人工智能隐私保护的需求,模型通常受相应防御技术的保护,研究一种黑盒、仅标签模型逆向攻击对进一步检测和分析模型的隐私鲁棒性及受保护程度同样具有重大意义。
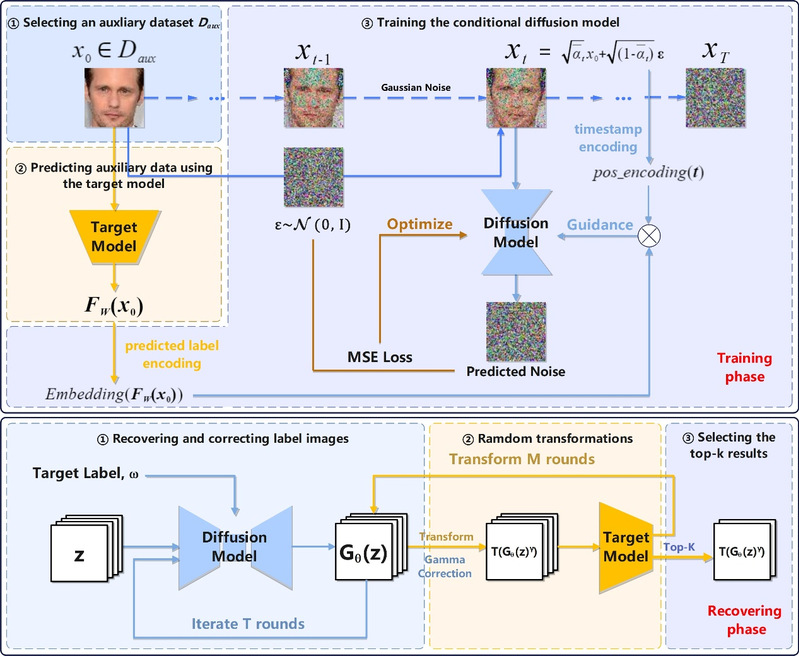
论文中提出基于条件扩散模型开发了一种仅标签模型逆向攻击方法,在敌手仅能通过访问模型获取预测标签的前提下,仍能够恢复训练集中特定目标的代表性数据。突破了现有黑盒、仅标签方法存在攻击模型未有效利用目标模型知识训练、攻击模型针对目标类只能获取唯一的生成结果,攻击会因扰动保护后的预测置信度影响等的技术问题。
具体而言,攻击模型在与目标模型任务相关的辅助数据集上进行训练,并使用相应辅助数据的预测标签作为条件来指导扩散模型的训练。这允许攻击者在恢复阶段将标准正态分布噪声、预定义引导强度和目标标签输入到条件扩散模型中,生成该标签下的多种代表性数据以供筛选,且无需额外优化算法介入。通过该领域最全面、系统、综合的实验结果表明,与相关工作中的攻击模型相比,本文方法在人脸识别任务中的最高攻击准确率达到56.13%,前五类攻击准确率高达84.54%,与现有最先进的白盒攻击效果媲美。其次,在相似性、真实性的评估下该方法均领先同领域最先进的方法,生成了更准确、真实、相似的数据,可用于进一步检测和分析受保护模型的隐私鲁棒性和受保护程度。

近年来,该团队教师承担了国家重点研发计划项目、工信部应用示范项目、国家自然科学基金、国防军工等国家级项目20余项,省尖兵领雁等省部级项目10余项。在IEEE TIFS、IEEE Systems Journal等国际重要期刊和会议发表论文90余篇,代表成果获得CCS2021(网络安全四大顶级会议)最佳论文、IEEE TrustCom2018最佳论文、IEEE AINA2011最佳学生论文以及CSS2009学生论文奖等。培养研究生多名入职党政机关,以及阿里巴巴、华为、海康威视等行业领先企业。







